[제 1 과목] 빅데이터 분석 기획
Chapter 01 빅데이터의 이해
Section 01 빅데이터 개요 및 활용
01. 데이터와 정보
1. 데이터의 구분
| 정량적 데이터 | 정성적 데이터 | |
| 구성 | 숫자 | 문자, 소리, 영상 |
| 용도 | DBMS, 스프레드시트 등 | JSON, 동영상, 음성 등 |
| 분석 | 쉬움 | 어려움 |
2. 데이터의 유형
| 정형 데이터 | 반정형 데이터 | 비정형 데이터 | |
| 구성 | 숫자 | 문자, 숫자 | 음성, 문자 |
| 용도 | DBMS, 스프레드시트 | JSON, XML, HTML | 동영상, 이미지, 음성 |
| 연산 | 가능 | 불가능 | 불가능 |
3. 데이터의 기능
- 암묵지 : 경험이나 생각 등이 외부에 표출되지 않고 개인이 지니고 있어, 전달이나 공유가 어려움
- 형식지 : 기록, 저장 등 실체화된 정보로 전달과 공유가 용이함
4. 지식의 상호작용
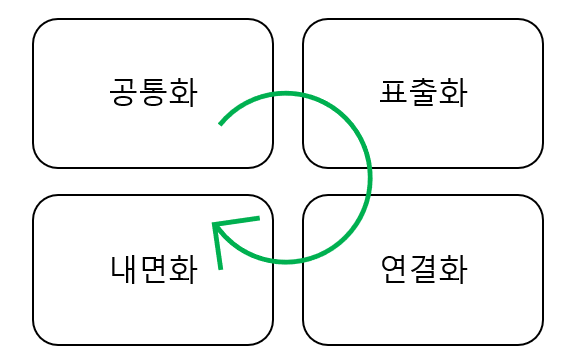
- 공통화 : 개인의 경험이나 지식을 공유하여 더 복잡한 암묵지를 형성
- 표출화 : 암묵지 -> 형식지로 표현
- 연결화 : 형식지를 체계화
- 내면화 : 형식지 -> 암묵지로 습득
5. DIKW 피라미드
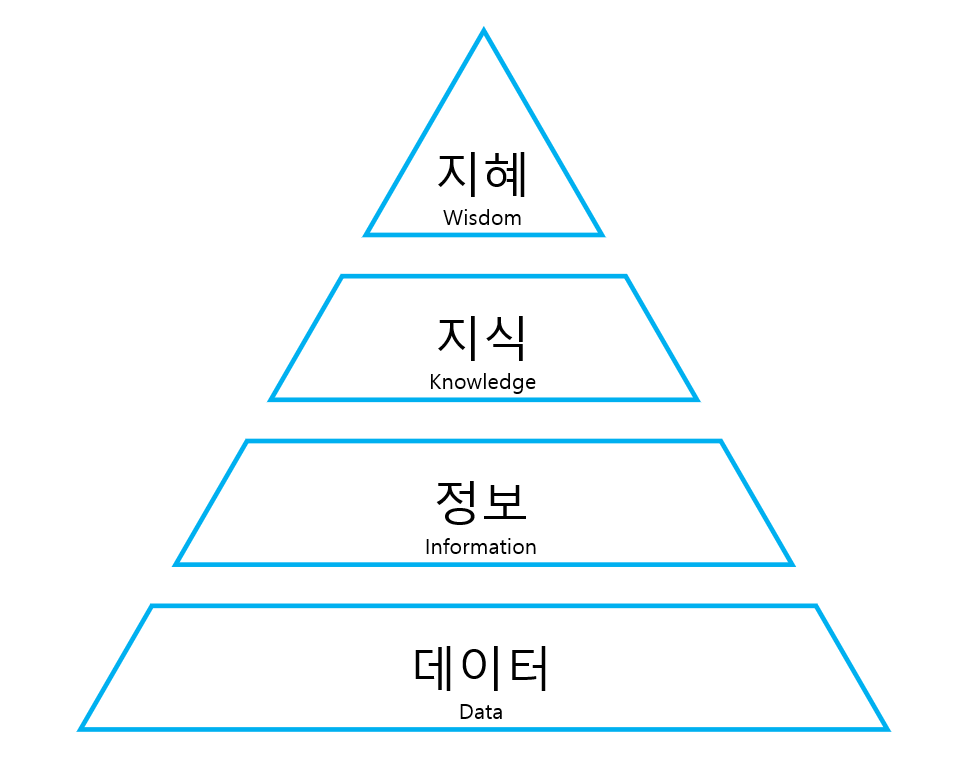
| 지혜 | 축적된 지식으로 새 아이디어를 도출 | ex) 다른 물건도 마트가 더 저렴할 것이다. |
| 지식 | 정보들과 개인적인 견해를 결합한 판단 | ex) A는 마트에서 구매해야겠다. |
| 정보 | 데이터들의 관계를 엮어 결합한 결과 | ex) 마트가 편의점보다 싸다. |
| 데이터 | 측정된 값이나 객관적인 사실 | ex) 마트에서 A 가격은 1000원, 편의점에서 A의 가격은 2000원 |
02. 데이터베이스
1.데이터베이스 관리 시스템 (DBMS)
| 관계형 DBMS | 2차원으로 표현된 테이블로 구성 |
| 객체지향 DBMS | 객체 형태로 구성 |
| 네트워크 DBMS | 그래프 구조로 구성 |
| 계층형 DBMS | 트리 구조로 구성 |
2. SQL
- 데이터베이스에서 활용되는 언어
- CRUD (= CREATE, READ, UPATE, DELETE)를 수행하여 데이터를 제어
3. 데이터베이스의 특징
- ACID
| 원자성 | 트랜잭션이 시작되면 작업이 모두 완료되거나, 모두 동작하지 않도록 한다. |
| 일관성 | 트랜잭션 이후, 결과로 인해 문제가 야기되지 않아야 한다. |
| 독립성 | 트랜잭션 중엔 독립 실행이 되어 다른 트랜잭션이 침범할 수 없다. |
| 지속성 | 트랜잭션이 완료되면 결과는 모두 반영이 되어야 한다. 트랜잭션이 실패하면 트랜잭션 이전과 같아야 한다. |
4. 데이터베이스의 활용
- OLTP : OnLine Transaction Processing, 온라인으로 접속된 단말들의 트랜잭션을 요청받아 수행하고, 결과를 전송
- OLAP : OnLine Analytical Processing, OLTP로 갱신되는 데이터베이스의 일정 시점을 분석에 활용
5. 데이터 웨어하우스, 데이터 레이크
| 데이터 웨어하우스 | 여러 소스로부터 수집된 데이터를 ETL(추출 및 변환)하여 정규화한 뒤 저장. 실시간 트랜잭션 과정보다는 데이터 저장에 최적화된 공간 |
| 데이터 레이크 | 데이터 출처 및 등록 시간을 포함하여 수정하지 않은 원시 데이터를 저장 |
03. 빅데이터 개요
1. 빅데이터의 변화
- 데이터 처리 시점이 사전 처리 -> 사후 처리로 변화
- 데이터 처리 범위가 표본 조사 -> 전수 조사로 변화
- 데이터 처리 기준이 질 -> 양으로 변화
2. 빅데이터의 특징
- 가트너 그룹의 3V 정의 이후, 2V가 추가됨
| 3V | +2V | |||
| 규모(Volume) | 유형(Variety) | 속도(Velocity) | 품질(Veracity) | 가치(Value) |
3. 빅데이터 활용
| 자원 | 데이터 확보 |
| 기술 | 처리, 분석, 관리 기술 |
| 인력 | 시스템 구축, 분석, 인문학 능력 |
04. 빅데이터의 가치
1. 빅데이터의 가치
- 석탄, 원유 : 산업혁명 급 변화를 가져다줄 것으로 기대
- 렌즈 : 상세하게 들여다 보는 현미경이 생물학에 기여했던 점에 비유
2. 가치 측정의 어려움
- 빅데이터의 가치는 측정할 수 없다.
- 당장 쓸모가 없더라도 추후에 사용될 수 있다.
- 데이터를 쓰는 목적, 방법에 따라 가치가 달라지므로 가치를 정의할 수 없다.
05. 데이터 산업의 변혁
1. 데이터 산업의 진화
- 데이터 처리 - 통합 - 분석 - 연결 - 권리 시대로 변화
| 데이터 처리 | 컴퓨터를 활용해 데이터를 처리, 새로운 가치 창출은 X |
| 데이터 통합 | 데이터 모델링과 데이터 관리 시작 |
| 데이터 분석 | 하둡, 스파크와 같은 빅데이터 관리 시작, 인공지능 상용화 |
| 데이터 연결 | 기업, 사람, 사물 등 다양한 주체와의 데이터 연동 ex) OpenAPI |
| 데이터 권리 | 마이 데이터 : 개인이 소유한 데이터에 대한 권리를 인정 |
06. 빅데이터 인력
1. 빅데이터 조직

- 집중형 : 별도의 전담 조직에서 분석 수행, 중요도에 따라 우선순위 설정, 부서별 업무가 중복될 수 있음
- 기능형 : 일반적인 구조, 각 부서에서 분석 진행, 부서끼리 독립적으로 수행하여 시각이 좁아 협업이 어려움
- 분산형 : 분석 인력을 전담 조직에서 직접 배치, 분석 결과를 전자적 차원에서 활용 가능
2. 데이터 사이언스
| 분석 영역 | 수학, 통계, 분석, 머신러닝 |
| 비즈니스 영역 | 커뮤니케이션, 스토리텔링, 창의력, 사고력 |
| IT 영역 | 프로그래밍, 데이터베이스, 엔지니어링 |
- 데이터 사이언티스트의 해석에 따라 방향이 달라진다.
3. 데이터 사이언티스트
| Hard Skill | 기술, 통계학, 이론, 지식 |
| Soft Skill | 창의적 사고, 스토리텔링, 커뮤니케이션 |
Section 02 빅데이터 기술 및 제도
01. 빅데이터 플랫폼
1. 구성
| 소프트웨어 계층 | 데이터 처리, 분석, 수집 |
| 플랫폼 계층 | 작업 스케줄링, 데이터 관리, 프로파일링 |
| 인프라스트럭쳐 계층 | 스토리지, 네트워크, 사용자 관리 |
02. 빅데이터 처리기술
- 데이터 수집 - 저장 - 처리 - 분석- 시각화
1. 데이터 수집
- 크롤링, 로그 수집, 센서, RSS, Open API, ETL
2. 데이터 저장
- SQL, NoSQL, 공유 데이터 시스템
- 병렬 데이터베이스 관리 시스템 : VoltDB, SAP HANA...
- 분산 파일 시스템 : GFS, HDFS
- 네트워크 저장 시스템 : SAN, NAS
3. 데이터 처리
- 분산 병렬 컴퓨팅, 하둡, 아파치 스파크, 맵리듀스
4. 데이터 분석
- 탐구 요인 분석 : 데이터 간 상관 관계 파악 후 분석
- 확인 요인 분석 : 데이터 간 통계적 기법을 통해 분석
- 분류, 군집화, 기계학습, 텍스트 마이닝, 소셜 네트워크 분석, 감성 분석
03. 빅데이터와 인공지능
1. 기계학습
| 지도학습 Supervised Learning |
훈련 데이터로 모델이 학습하고, 주어진 데이터에 대해 예측 및 분류 |
| 비지도학습 Unsupervised Learning |
정답이 없는 데이터들을 군집화하여, 패턴이나 새로운 결과를 탐색 |
| 강화학습 Reinforcement Learning |
데이터의 유무를 떠나 보상을 받으며 행동하며, 보상을 최대화하거나 목표를 달성하는 것이 목적 |
2. 전이학습
- 다른 문제를 해결하기 위해 학습된 모델을 비슷한 과제에도 활용하는 과정
- 데이터가 적어 학습이 어려울 경우, 이미 학습된 모델을 활용할 수 있어, 시간 절약 및 데이터 부족을 해결할 수 있음
- 전이학습 기반 사전학습모형, BERT(구글의 언어인식 사전학습모형)
3. 인공지능 기술 동향
- 프레임워크 보급 : Tensorflow, Keras, Pytorch
- 생성적 적대 신경망 GAN : 두 개의 인공신경망이 가짜의 진위여부를 판별하며 점점 진짜와 구별하기 어렵도록 학습
- 오토 인코더 : 라벨 설정 최적화
- XAI (eXplainable AI) : 학습 과정을 숫자나 자연어로 보여줌
- AutoML : 데이터 전처리, 모델 선택, 하이퍼파라미터 최적화를 자동화
04. 개인정보 비식별화
1. 비식별 조치
| 가명처리 | 개인 식별이 가능한 데이터를 다른 값으로 대체. 휴리스틱 가명화, 익명화, 암호화 등 |
| 총계처리 | 개인 정보에 통계값을 적용하여 특정하지 못하도록 함. 총합, 부분합 등 |
| 데이터 삭제 | 특정 데이터의 값이나 일부를 삭제. 식별자 삭제, 부분 삭제 등 |
| 데이터 범주화 | 대푯값이나 구간값으로 변경. 범주화 등 |
| 데이터 마스킹 | 데이터의 전체 또는 일부를 다른 값으로 변환. 잡음 추가, 공백, 대체 등 |
2. 적정성 평가
| k - 익명성 | 동일한 값을 가진 레코드를 k개 이상 만들어 개인을 특정하기 어렵도록 만듬 |
| i - 다양성 | 각 레코드에 i개 이상의 다양성을 가지도록 하여 추론 방지 |
| t - 근접성 | 전체 데이터와 특정 데이터의 분포 차이를 t 이하로 만들어 추론 방지 |